Intro¶
What is contained in this project.
- A list of tasks which covers many basic points in spider development, each task is a short exercise. You will be able to solve real complex problem after you solve the simple tasks step by step. This idea derive from code kata
- Some advanced tips and notes which help you improve the development productivity, and it will introduce you some great tools.
Supplement instead of alternative of scrapy doc¶
Scrapy doc is a good start for people who want to learn to write spider by using scrapy. Since scrapy doc mainly focus on the components and concepts in scrapy, some points which make sense in spider development with scrapy are missed in the doc. That is why I created this project.
I did not talk much in componetns of scrapy in this doc. It is strongly recommend user to read scrapy official doc first to have a basic understanding such as how to create spider and how to run spider in scrapy. You might can not get some points here if you have no idea how the spider work in scrapy. If you have question for scrapy, please check it in official doc first.
Support Platform¶
OSX, Linux, python 2.7+, python 3.4+
Get started¶
First, you should take a view of the workflow figure of this project to know how this project work and read basic concepts in doc.
Secondly user will choose one task in online doc of project and get started, it is recommended to solve the task in doc order considering the learning curve. User should create spider as doc asked and run the spider to get the data as expected. There is a sample spider callled basic_extract in the project, just follow it to create new one and troubleshoot If user can not make the spider to work, you can also check the working spider code in the solution repo which I will push later.
Thirdly user can get some advaned advise or tips in advanced topic , you can learn how to enhance your browser to make it more helpful in spider development or other stuff.
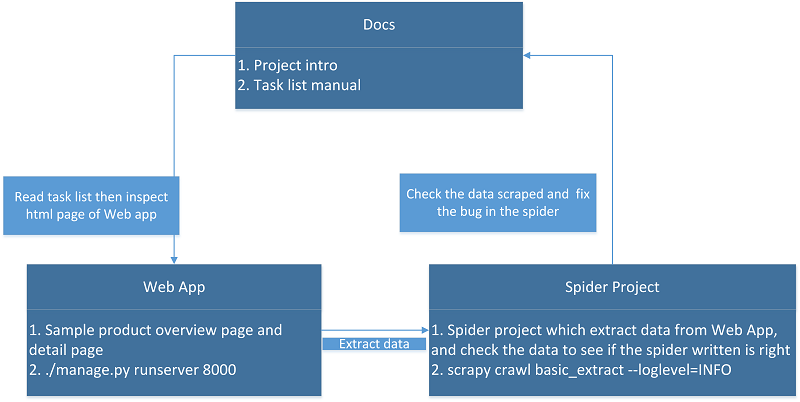
Project structure¶
Here is the directory structure:
.
├── docs
│ ├── Makefile
│ ├── build
│ └── source
├── requirements.txt
├── spider_project
│ ├── release
│ ├── scrapy.cfg
│ └── spider_project
└── webapp
├── content
├── db.sqlite3
├── manage.py
├── staticfiles
├── templates
└── webapp
docscontains the html documentation of this projectwebappis a web application developed byDjango, we can see this app as a website which show us product info and product links, and we need to write spider to extract the data from it.spider_projectis a project based onScrapywhich we should write spider in it to extract data fromwebapp.
First glance¶
So here is an example product detail page, it is rendered by webapp mentioned above.
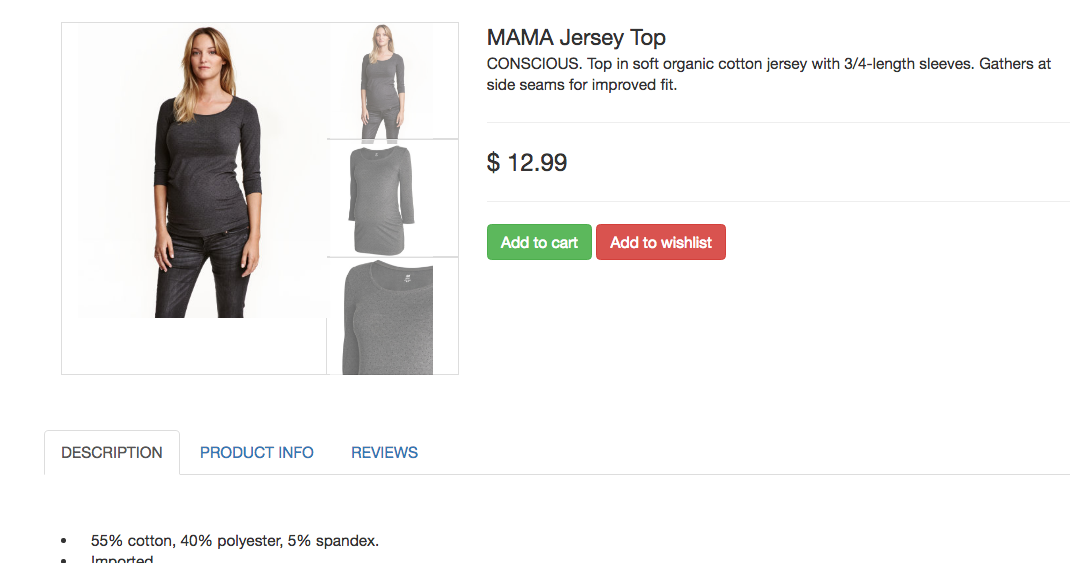
Now according to task in the doc, we need to extract product title and desc from the product detail page
Here is part of spider code:
class Basic_extractSpider(scrapy.Spider):
taskid = "basic_extract"
name = taskid
entry = "content/detail_basic"
def parse_entry_page(self, response):
item = SpiderProjectItem()
item["taskid"] = self.taskid
data = {}
title = response.xpath("//div[@class='product-title']/text()").extract()
desc = response.xpath("//section[@class='container product-info']//li/text()").extract()
data["title"] = title
data["desc"] = desc
item["data"] = data
yield item
We can run the spider now, the spider will start to crawl from the self.entry and it will check the data scraped automatically. if the data scraped have some mistake, it will give the detail of the error and help you get the spider work as expect.