Ajax extract¶
Goal¶
Recently many websites get product info through ajax request so it make sense for us to quickly figure out how it works and find a way to get the real data.
If you have no idea what ajax is, read it
Entry¶
If you have no idea what entry and taskid is, check Read before you start
Remember to config WEB_APP_PREFIX which located in spider_project/spider_project/settings.py
Entry:
content/detail_ajax
If your webapp is working on 8000, click the link below
Detail of task¶
In this task we try to crawl product title and price info. You should find out that the value in html is not the one you see in your brower.
You can check the network panel of your brower to filter out ajax url the browser used and try to implement it in your spider. You should yield a request in parse_entry_page method to minic ajax request.
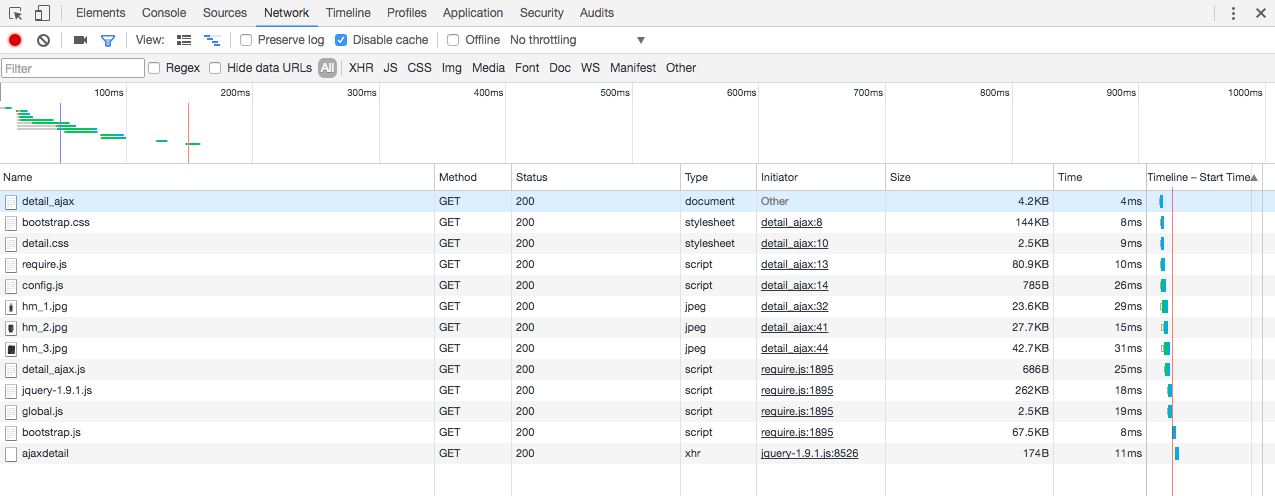
Once you finish the coding just run scrapy crawl ajax_extract --loglevel=INFO to check the output
The final data should be:
[{
"data": {
"price": "$ 12.99",
"title": "MAMA Jersey Top"
},
"taskid": "ajax_extract"
}]
Advanded¶
Note
You must be able to use tools of browser to analyze http request. see Use web dev tools.